
Содержимое сайта публикуется на условиях CreativeCommons Attribution-ShareAlike 3.0 или более поздней версии. Программные коды в тексте статей — на условиях GNU GPL v2 или более поздней версии.
Документация по совместной работе с репозиторием drupal.ru – https://docs.drupal.ru/code
Drupal – торговая марка Дриса Бёйтарта

12+
Друпал и нейросети
Я вообще пока очень слабо себе все это представляю, вопросы у меня поэтому могут быть ну совсем примитивными.
На разных серверах было бы лучше конечно, потому что для нейросети у нас и так будет скорее всего сервер с минимумом необходимой мощности. В идеале, если сеть будет у меня на месте, а сайт удаленно.
Друпал и нейросети
Спасибо большое! Почему именно python?
Какие главные преимущества для моих задач по сравнению с php?
Я вообще смотрю в сторону FANN из бесплатных ПО для нейросетей. Ну или могу рассмотреть платные какие-то, если возможности конкретно под мои задачи будут больше.
Придется ли идти на ограничения по функционалу в случае, если я буду делать интеграцию через базу или API (в таком случае проще делать экспорт и потом в ручном режиме загрузить в базу).
Друпал и нейросети
Модель процессов в биологии и медицине, прогнозирование, анализ данных
Можно ли вставить картинку через CTRL+C - CTRL+V? CKEDITOR, IMCE
Нет
Так в чем завязывание? в текстовом поле же будет CKEditor доступен при желании?
Файлы с описаниями в ноде
Здравствуйте! Возникла еще задача вывести информацию о формате файлов текстом и убрать шапку

Это в админке или в каком шаблоне правится или как узнать?
Также хотелось бы добавить иконку отдельно для скачивания. Т.е. чтобы при щелчке по названию файл открывался, а при щелчке по иконке скачивания - скачивался (может есть модуль для этого?).
Можно ли вставить картинку через CTRL+C - CTRL+V? CKEDITOR, IMCE
В отдельное поле можно с помощью filefield_sources и ctrl c и прямо перетягивать мышкой.
Если стандартный порядок следования текста и картинок у Вас, то можно сделать поля текста и картинки поочереди, сколько нужно раз;
или вообще с feeds автоматизировать, а с file_entity можно будет и альт, и заголовки с feeds подгуржать
unexpected '[' in h5p.classes.php
Да, это специфические модули. Там был модуль что-то типа рабочего пространства онлайн с совместимостью с онлайн "комнатой" типа скайпа. Уже не помню название. он работал только с 5.3. Но были другие сложнсоти с ним, пришлось все равно от него отказаться. И еще какие-то тоже требовали 5.3. уже сейчас не помню названия.
unexpected '[' in h5p.classes.php
Спасибо.
Тогда пока вижу два варианта решения
а)повысить php
(но на Друпал 7 у некоторых модулей были проблемы даже с 5.6., так что может и не получиться )
но буду пробовать
б)закачать старую версию модуля на сайт вручную, потому что старая работала на этой версии php
Буду пока делать.
Сайт пока пришлось восстановить с помощью drush arr
drush arr /home/.../drush-backups/archive-dump/20181101193701/dumpname.tar.gz
Файлы с описаниями в ноде
file_force выводит файл для прямого скачивания с подписью описанием файла. Но все же чтобы избежать доп модуля токен хорошо было бы настроить тогда можно было бы обойтись без file_force.
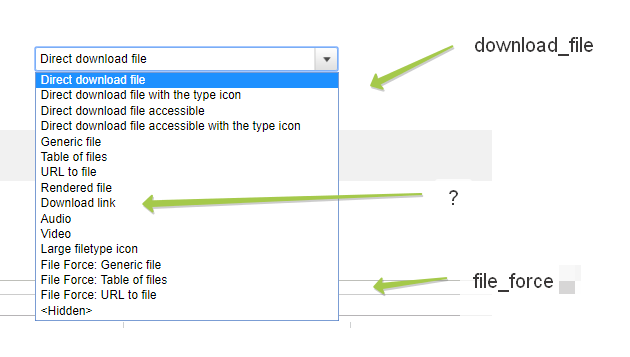
Также после теста модулей
file_force
и
download_file
выкладываю скрин возможностей настройки в отображении поля, которые они добавляют
Файлы с описаниями в ноде
При попытке найти описание, как настраивать file_force, выяснилось, что нужно настраивать в настройках отображения (нигде не удалось найти инструкции, только на странице модуля написано, что он добавляет
"Formatters for your node fields in the "Display Fields" interface")
Файлы с описаниями в ноде
Попробую тогда эти модули. Спасибо
Файлы с описаниями в ноде
Спасибо.
У меня будет страница отдельно именно для скачивания и я хочу попробовать именно на ней настроить скачивание. Но вот из модулей 2 удалось найти
https://www.drupal.org/project/file_force
и
https://www.drupal.org/project/download_file
Но смущает что у них всего по 5-7 тысяч использующих сайтов
Файлы с описаниями в ноде
Спасибо
А если модулем дополнительно, то каким лучше или лучше на сервере все же?
А где можно почитать по настройками на сервере или просто что сказать в службе поддержки на хостинге?
Файлы с описаниями в ноде
Спасибо. Описание появляется. Но при этом при щелчке мышью не происходит скачивание файла, а файл (типа изображение) открывается в новом окне. А как сделать, чтобы он скачивался или добавить рядом с ним кнопку для скачивания (можно ли сделать без доп модулей типа file download)?
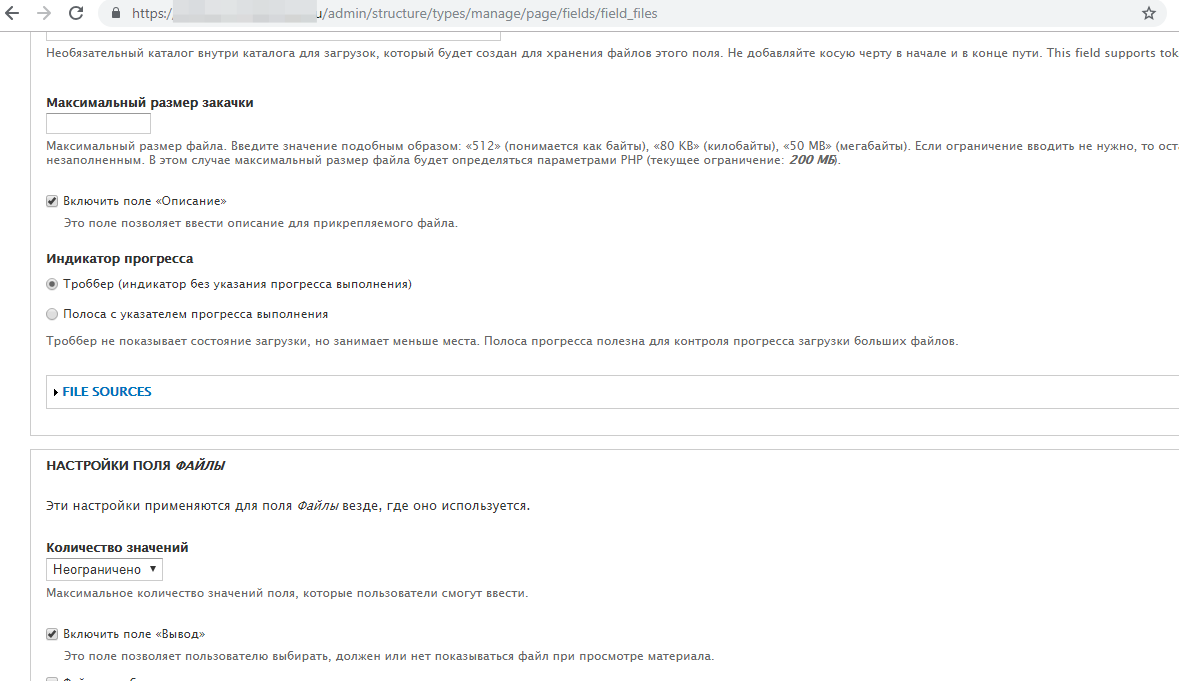
Где добавляю галочку выкладываю на всякий случай
Как убрать автоматическое удаление табуляции и переносов строк
UPD: Удалось создать свой рабочий формат
Настройки такие как на картинке
Как убрать автоматическое удаление табуляции и переносов строк
с plain text работает, как настроить какой-то другой правда пока не понятно
Как убрать автоматическое удаление табуляции и переносов строк
Спасибо. Но вот я например делаю filtered html и проблема сохраняется.
Внутри формата на что обратить внимание?
я в нем для пробы снимаю галку с пункта
"Заменять переводы строк соответствующими HTML-тегами (т.е.
и )" и
"Исправлять неправильный и обрезанный HTML"
Все равно обрезает
id подшивки book
Спасибо. Будут и теги. Просто иногда удобно сразу с нужной иерархией добавлять дочернюю страницу одной кнопкой, также удобный готовый функционал, не нужно настраивать views чтобы смотреть подшивку и сразу есть возможность перейти на уровень вверх или прочитать предыдущий и следующий материал этого же уровня.
id подшивки book
Спасибо. Тогда буду смотреть в URL. Попробую
Ускорение работы с полями и типами материалов
Спасибо большое! Я обязательно все очень внимательно проанализирую и постараюсь сопоставить этот пример со своей задачей (у меня особенность, которая накладывает ограничение на такую архитектуру при первом взгляде – что значение атрибутов у меня часто складываются из нескольких терминов таксономии и еще некоторых типов полей, и мне нужно потом иметь возможность выводить это все в поиске по отдельности, т.е.
Ускорение работы с полями и типами материалов
В одном из длинных "нечитаемых" комменатриев без абзацев )))
который начинается со слов "По факту то что нужно сделать это смесь научного исследования с одновременным представлением его online (просто удобного обзора) и результатов ручной сортировки сведений
(либо систематизации) для более удобного поиска того, что часто используется."
Описано.
Но возможно стоит сделать более четкое описание как часть ТЗ, если не понятно, то что там написано.
Ускорение работы с полями и типами материалов
Спасибо.
А какие еще могут быть более правильные (хотя бы с точки зрения скорости создания структуры) варианты?
Я пока для Друпал 7 вижу только три варианта:
1)Делать bundle нод
Ускорение работы с полями и типами материалов
Спасибо. А можно подробнее, что именно будет закрыто и как пейджеры будут закрыты?
Где почтитать про это?
Ускорение работы с полями и типами материалов
Но то что можно накликать для представлений для нод на Друпал 8 можно кодить или делать файлами, верно?
Ускорение работы с полями и типами материалов