У меня было импортировано на сайт пару сотен страниц через feeds.
Потом они были отредактированы массово (теги поменялись и т.д.) и нужно было их снова загружать.
Так как в feeds заголовок был настроен как "not used as uniq", то чтобы случайно не получилось дублей, старые ноды были удалены, а новые загружены заново.
Путь, который делает pathauto по заголовку у них получился такой же. И предполагалось что для поисковиков это будут те же страницы.
Но, старые пути просто с чистыми ссылками типа node/1 теперь попали в индекс со статусом 404 (при том что раньше они там не отражались, по крайней мере у меня в статистике обхода их нигде не было).
Точнее они в списке в статистке обхода, в "Страницы в поиске" их как нет так и не было.
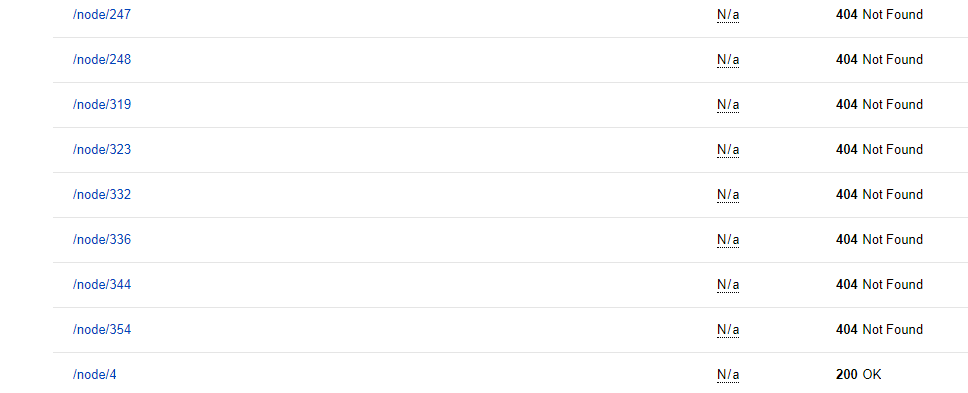
Знать бы что они видны Яндексу, так проще было в feeds настроить заголовки "used as uniq" и просто обновить ноды... Но теперь что делать?
Три вопроса:
1)Это вероятно не очень для сайта то, что у него столько страниц со статусом 404?Страниц пару сотен.
2)Как теперь это исправить?
-может что-то в настройках global redirect?
-или просто запретить несуществующие страницы для индексирования в robots.txt?
Как это праивльно сделать и нужно ли?
-еще иногда предлагают вариант перенаправлять 404 ошибки на главную
3)В чем причина? Видимо Яндекс их видел все же, но в статистике обхода отражал уже путь сделанный с pathauto?


Комментарии
Уважаемый, без обид, но вы ерундой занимаетесь.
Делайте сайт для пользователей, а не для Яндекса.
Ну человек взялся за ичучение поисковиков. Вот смотрю теперь и все анализирую. Очень много двучтений по разным вопросам. Поэтому и всплывают такие темы. Простите, если яндекс увидит, что на сайте 800 удаленных страниц, то как на это отреагирует? Или если 404, то все в порядке?
Правильно я понимаю, что 404 решает проблему удаленных страниц полностью?
Просто иначе очень много удаленных страниц, если там что-то не так настроено, то поисковик запросто скинет на пару сотен позиций вниз, то тогда, как пользователи попадут на сайт? Ну представьте, что Вас постоянно приглашают в гости, Вы приходите, а там закрытая дверь 800 раз? Вполне логично, что в поисковике может быть мехнизм за такое выкидывать из поиска сайты? Или нет. Я вот читаю и однозначного ответа на эту тему не вижу.
Если у Яндекса где-то в инструкции написано, что количество страниц со статусом 404 не имеет значения для индексирования, то мне только спокойнее. А так дело в том, что пользователи пока могут попасть на сайт только через поисковики. Другие способы я пока не могу использовать.
Со временем выкинет эти страницы из индекса.
P.S. 100 позиций вниз - это серьезный фильтр, 404 страницы, точно, такого не сделают.
P.P.S. Алгоритм ранжирования вы никогда не узнаете.
Спасибо. Вот здесь в комментах (опять же это не инструкции, и авторитет относительный) пишут
"если код 404, то бот продолжает ломиться к этой стр, а если 410 – забивает"
Т.е. тогда получается мне нужно переделать на 410? иначе поисковики будт постоянно сканить эти 800 штук с 404?
А дальше вообще непонятно пишу "очевидцы"
"При внедрении 410 кода вместо 404 яндекс их все добавлял в индекс. И он рос на глазах. Вернули 404 – индекс спал."
Как минимум большое количество ошибок 404 снижает обход нормальных страниц роботом.
"Исходя из концепции краулингового бюджета, процесс обхода 404 SOFT страниц неизбежно займет драгоценные лимиты сканирования. Иными словами, вместо того, чтоб сканировать нужные вам URLs, Googlebot будет сканировать Soft 404 ошибки. А это уже снижает видимость важного контента на вашем сайте. Поэтому, неудивительно, что при устранении ошибок Soft 404 наблюдается тенденция к улучшению ранжирования сайта в SERP Google."
А чистые ссылки это же тоже не исходные? На них же перенаправляется с какого-то другого адреса? Или все же сразу друпал чистые создает? Иначе, если даже убрать эти 404 на страницах с чистыми ссылками, то тогда попадут в индекс те, что были до формирования чистых ссылок? И еще добавиться 800 штук с 404?
Там же сначала какой-то другой адрес? потом чистая ссылка, потом работает pathauto? Редирект с чистой на эту pathauto исчез - в индекс попали чистые ссылки с 404. Т.е. убирать эти страницы из поиска нужно так, чтобы когда они исчезнут и вместе с ними редирект с исходных на чистые, чтобы не появились уже исходные со статусом 404?
Наверное, самое оптимальное будет все же как-то заменить 404 на 410.
Как это лучше всего сделать?
Это хотя бы приведет к тому, что поисковики точно и быстрее поймут, что не нужно обходить эти страницы
Скрины описания Яндекса по ошибкам
__________________________________________
Или может не полениться и посмотреть номер первой страницы, созданной после массовго удаления страниц (например будет 801), и предыдущие закрыть в роботс, в элнктронной таблице какой-то создать список автоматом
dissallow: /node/100
...
disallow: /node/800
Но я подозреваю, что столько фигни в роботс - тоже перегруз для робота
Здравствуйте! Еще один вопрос. А у Вас Яндекс при включенном pathauto обходит все страницы, с которых делалось перенаправление 301? Или они должны быть как-то закрыты?
Например, если у меня есть нода с адресом
site.ru/node/610
которая перенаправляется на адрес генерированный pathauto
site.ru/myname
то правильно ли, что у Яндекса в статистике обхода отражается

И вообще у меня в основном в обходе только страницы с адресом вида node/number

хотя у меня включен pathauto и еще много адрсов вручную создается.

Может у меня что-то в конфигурации неправильно после настроек, которые как раз недавно делались на admin/config/search/path
Из настроек основная, которая была сделана:
был сокращен путь
Default path pattern (applies to all content types with blank patterns below)
с
content/[node:title]
на
[node:title]
Скорее всего у вас каноникал неправильный. По умолчанию он имеет вид node/:nid.
Спасибо. А как поправить?
и
что Вы имеете ввиду под "он"?
Он - это каноникал. Правится в настройках метатегов.
Спасибо. На admin/config/search/metatags/settings,
?
Что-то не могу найти там. Где, в какой вкладке?
В каждой из них))) но естественно, надо начать с глобальной, т.к. все остальные наследуются от неё.
Спасибо. Я похоже вообще где-то не той странице

_________________________________________________________________________________________________

У меня после включения модуля metatag вот такие настройки конфигурации доступны
("вкладки" я имею ввиду "раскладушки" )
На вкладке defaults. Вообще странно, что вы так увлечены SEO, но не умеете настраивать метатеги.
Спасибо. Это новое увлечение )

ну и я наверное в этой области пока туго соображаюУ меня настроено сейчас
[current-page:url:absolute]
При попытке найти манаулы по узкоспециализированной теме :
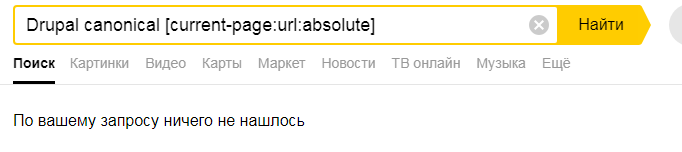
_______________________________________________
Может порекомендуете где об этом лучше почитать
И на что нужно исправить? на
[current-page:url:node/:nid]
Смотрите браузер доступных токенов. Ищите токен, в котором фигурирует alias.
Спасибо. самое близкое [url:alias]
Смотреть на /admin/help/token ?
или можно на https://www.drupal.org/node/390482
там список даже больше
Но возможно что не усе из них у меня доступны
Вписывать в
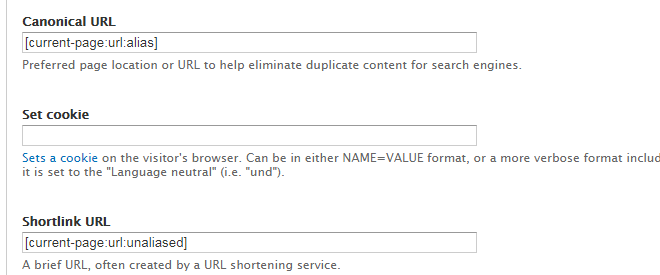
поле "Canonical URL":
" [url:alias]"?
А куда-то нужно еще помещать [node:metatag:canonical]
На страницу которую я хочу сделать основной? (как и где?)
этот и должен быть
Где править теперь понятно, но не понятно, как правильно? "node/:nid" мне не подходит? править на токен с alias (как ниже написано?)
Не совсем я с этим понимаю.
А если у меня везде работает pathauto, не используются нигде адреса node/nid,
может проще вообще настроить в роботс
Disallow: /node/
?
Алехо, самый первый коммент был в тему.
Вы рано заморачиваетесь с этими вопросами, мне кажется что скорее всего даже сайт не запустили еще...
Оставьте редирект (глобал редирект) и он все нормально сделает с урлами node/id>>url(ЧПУ).
А ссылку на Деваку дали зачем? Хоть разобрались что такое софт 404?
Или вы думаете это не от слова мягкий, а от слова программное обеспечение?
Спасибо. Но думаю что все же не совсем на пустом месте. К тому же у меня подтвержается ситуация с тем, что робот меньше обходит нормальных страниц, а половина в статистике обхода - это 404. Т.е. про софт я почитаю еще подробнее в чем отличие от просто 404 Но смысл в том что и с простыми 404 я вижу, что "вместо того, чтоб сканировать нужные вам URLs"... поисковик сканирует 404.
Самое простое удалить их через роботс панель Яндекса, я просто сомневаюсь и изучаю сервисы массовой проверки статуса ответа, так как если не проверить перед составлениме списка, то есть вероятность случайно среди удаленных нормальные прихватить.
Продолжаешь маяться бесполезным трудом?)
Естественно ПС должен сначала просканировать 404, иначе как он узнает что их больше нет?)
После этого он уже будет сканировать что есть на сайте.
Важное в твоем случае чтобы не было битых ссылок внутри сайта. Все. На этом в текущий момент более чем достаточно остановится.
Впрочем если много свободного времени, то конечно.
Спасибо за советы.
Можно врчуную в панели Яндекса удалить эти страницы, предвариательно в роботс добавить disallow для них, иначе отклонит
Вообще в глобал редиректе можно выставить 301 для этих страниц.
Спасибо.
Вы имеете ввиду выставить на странице управления конфигурацией? где именно?
301 для каких страниц выставить? которые были с 404?
В твоем случае не поможет, потому что ты удалил ноды и создал новые.
Это уже другие сущности, никак не связанные между собой. Если бы у тебя поменялись урлы в старых нодах, то да, модуль был бы крайне (он и есть такой) полезным.
Немного не так. Модуль redirect может "Автоматически создавать перенаправления, при изменении синонимов URL." а так же у него есть страница "Исправление 404 страниц"

И еще проиндексировалась страница с адресом
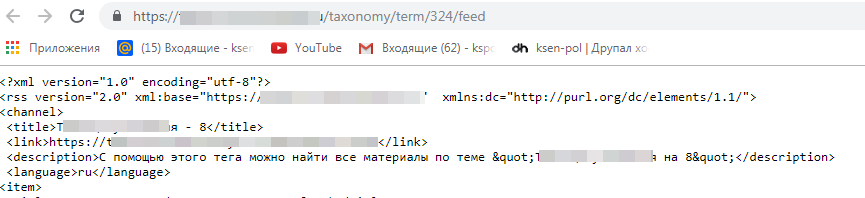
term/324/feed
но на ней открывается почему-то код а не нормальная страница
Так должно быть?
Да. Это rss-лента.
Выкладываю скрин сводки после удаления дубля и после удаления лишних страницы
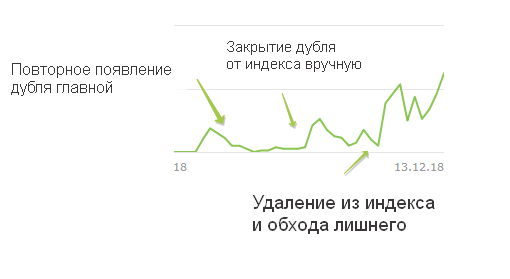
Вроде индексирование улучшилось. Но есть проблема

Старницы вида /ru
были закрыты с помощью
Disallow: /en*
Disallow: /es*
Disallow: /it*
Disallow: /de*
И они были добавлены в Яндексе
Но сейчас дошло, что могут же быть адреса начинающиеся на en, de и т.д. Таким образом они же тоже будут заркыты
Нужно было закрывать наверное
Disallow: /en/*
Disallow: /es/*
Disallow: /it/*
Disallow: /de/*
И наверное придется добавить теперь
Allow: /en*
Allow: /es*
Allow: /it*
Allow: /de*
Но опять вопрос с порядком
Верхняя директива будет основной или нижняя. Как располагать? И сейчас читаю по этой теме, вижу, что правила могут быть разные в Яндексе и Гугле и вообще они периодически меняются. Буду смотреть на практике, и если есть какие-то советы, то учту.