Здравствуйте, хочу запретить индекс страниц словаря таксономии Тегов / Меток
стоит Pathauto и Глобал редирект
Делаю так в робот.тхт
# Paths (clean URLs)
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /filter/tips/
Disallow: /node/add/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: /user/login/
Disallow: /user/logout/
Disallow: /tags/ - вот машиное имя словаря
# Paths (no clean URLs)
Disallow: /?q=admin/
Disallow: /?q=comment/reply/
Disallow: /?q=filter/tips/
Disallow: /?q=node/add/
Disallow: /?q=search/
Disallow: /?q=user/password/
Disallow: /?q=user/register/
Disallow: /?q=user/login/
Disallow: /?q=user/logout/
Я правильно понимаю что будет запрещена индексации везде где присутствует слово tags?
+ сайт на анг и рус языке. Подействует ли оно, если правильно написано канешн, на двух языках?


Комментарии
Должно работать. Вот только интересно, в чём смысл. Обычно теги наоборот индексируют, чтобы была лучше перелинковка.
а дубли анонсов не как не влияют?
Нет конечно. С чего вы взяли, что анонсы - это дубли?
Вопросы по seo - это все таки не тот форум.
Хотя по сео-маразмам - у нас на аутсорсе есть адекватный сеошник. И он мне кинул ссылку на рекомендации яндекса по переезду на https. И я вдруг понял - это не сеошники крезанутые, а поисковики. Ну и сеошники тоже.
Поисковикам, иногда, приходится принимать не очень удобные для владельцев сайтов меры, которые бывают с виду странными, но обычно являются каким-либо компромиссом, и оправданы технически. Например, для поисковика https://domain.tld и http://domain.tld это просто два совершенно разных ресурса, и не случайно - так может быть не только в воображении создателей поисковика, но и в реальности. И им приходится учитывать, не самый частый случай, а наиболее общий. Отсюда и эти сложности со склейкой "зеркал".
А вот с СЕОшниками всё куда хуже. В основной массе, это просто гадальщики на кофейной гуще, которые не знают примерно ничего, и дают какие-то рекомендации на основе того, что где-то что-то услышали.
Ох уж эти SEOрасты... Поразвелось, что скоро SEOрастпарады можно будет проводить
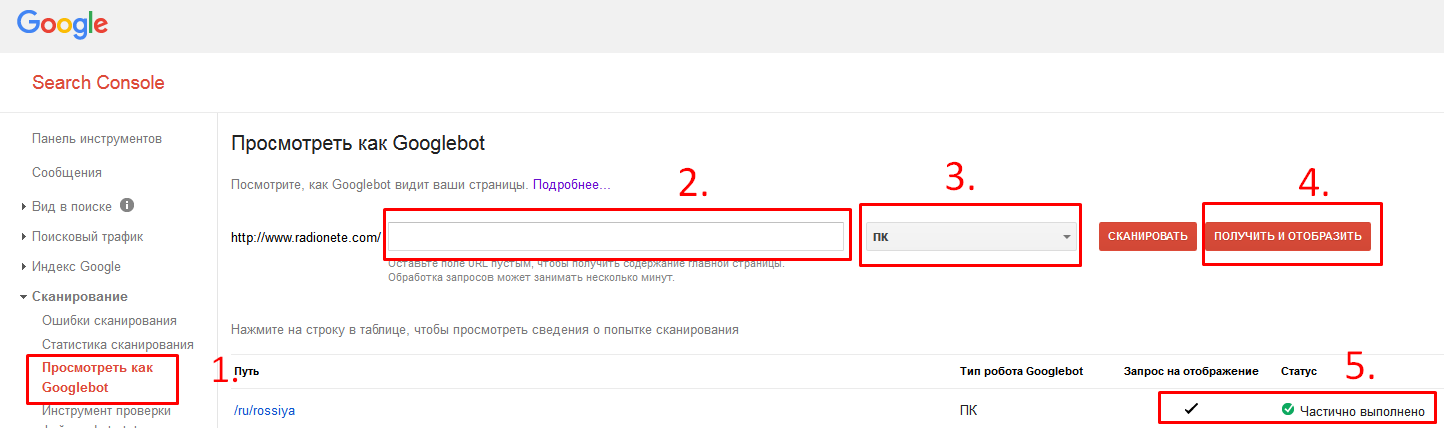 Перейти в раздел посмотреть как Googlebot (1), прописать URL (2), выбрать вариант сканера (3), выбрать вариант сканирования (4), нажать на надпись (5) для дальнейшего ознакомления/изучения причин не полного отображения, ознакомится с содержанием и причиной
Перейти в раздел посмотреть как Googlebot (1), прописать URL (2), выбрать вариант сканера (3), выбрать вариант сканирования (4), нажать на надпись (5) для дальнейшего ознакомления/изучения причин не полного отображения, ознакомится с содержанием и причиной 

А теперь по существу.
Запомните, что Disallow: / в robots.txt запрещает сканирование, а не индексирование!!!
Для запрета индексирования надо использовать
<meta name="robots" content="noindex">Таким же тегом надо удалять ненужные страницы из индекса поисковиков, перед этим открыв к ним доступ в robots.txt
Что касается конкретно вопроса ТС, то могу посоветовать подобрать оптимальный вариант методом перебора.
Подробнее:
а) Регистрируйте сайт в SC (Search Console)
б) Настройте на Ваш взгляд правильно robots.txt
в) (см. картинку)
г) если всё устраивает - выпить спокойно холодного пива, если нет - повторить пункты б) + в)
Согласен, что тут не форум по SEO, но тем не менее даже тут есть раздел http://drupal.ru/forum/SEO
Тс не в тот раздел поместил вопрос.