Здравствуйте! Появились глюки с индексированием Яндексом commerce kickstart.
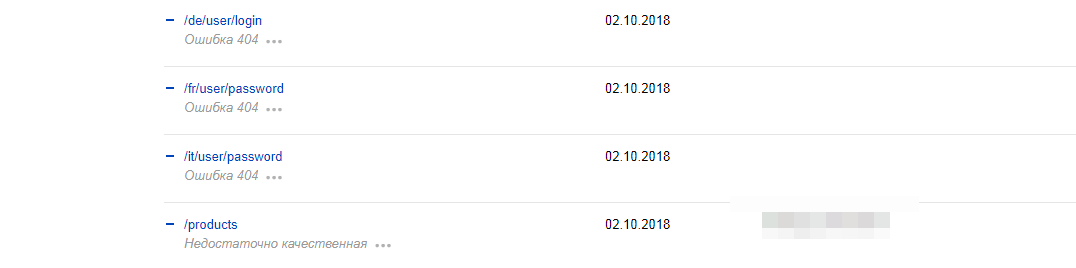
При том, что языки на сайте всегда были только русский и английский, и сейчас вообще включен только русский, в индекске много страниц с другими языками со статусом 404 (в частности /fr/user/registe, /it/node/253, /de/node/249 - при том что мною было создано только 1 нода), также есть еще сслыки на страницы, которые идут в качестве образца по умолчанию при установке дистрибутива
типа /bags-cases/drupal-commerce-iphone-case с кодом 200, хотя все материалы, которые ставились по умолчанию сначала были сняты публикации, потом удалены.
Как это исправить?
Также еще появляются какие-то странные символы через пару недель после установки дистрибутива уже не в первый раз.
Скришноты прилагаю
| Вложение | Размер |
|---|---|
| 10.27 КБ | |
| 7.44 КБ | |
| 13.93 КБ | |
| 5.25 КБ | |
| 14.61 КБ | |
| 7.62 КБ | |
| 51.86 КБ | |
| 108.72 КБ | |
| 29.91 КБ |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Комментарии
Нет никаких глюков, все в пределах алгоритма Яндекса.
Почитать бы вам не помешало - https://yandex.ru/support/webmaster/
Спасибо. Инстуркцию еще раз почитаю. Имею ввиду, что глюки не у Яндекса, а глюки в моих настройках, и я хочу их исправить.
Или я чего-то не понимаю?
У меня на сайте сейчас мною создан один блок с текстом на главной и одна нода,
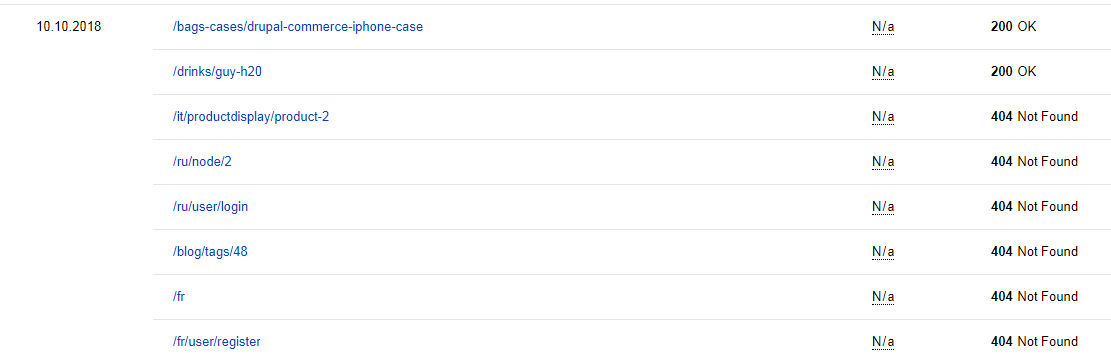
при этом в дистрибутиве было несколько десятков материалов с рекламой от создателей, все были сняты с публикации и удалены, продолжают быть в обходе Яндекса, при чем не только со статусом 404 но и со статусом 200.
Т.е. 404 это вероятно страницы, которые раньше были в обходе и удалены. А 200? Откуда они, если все удалено? Можно ли где-то в настройках найти и исправить это? Или нужно по каждой ссылке проходить и удалять вручную?
А по user/login есть где-то в инструкции Яндекса? Французский, немецкий и итальянский языки вообще не влючались на сайте.
Откуда они в поиске не пойму?
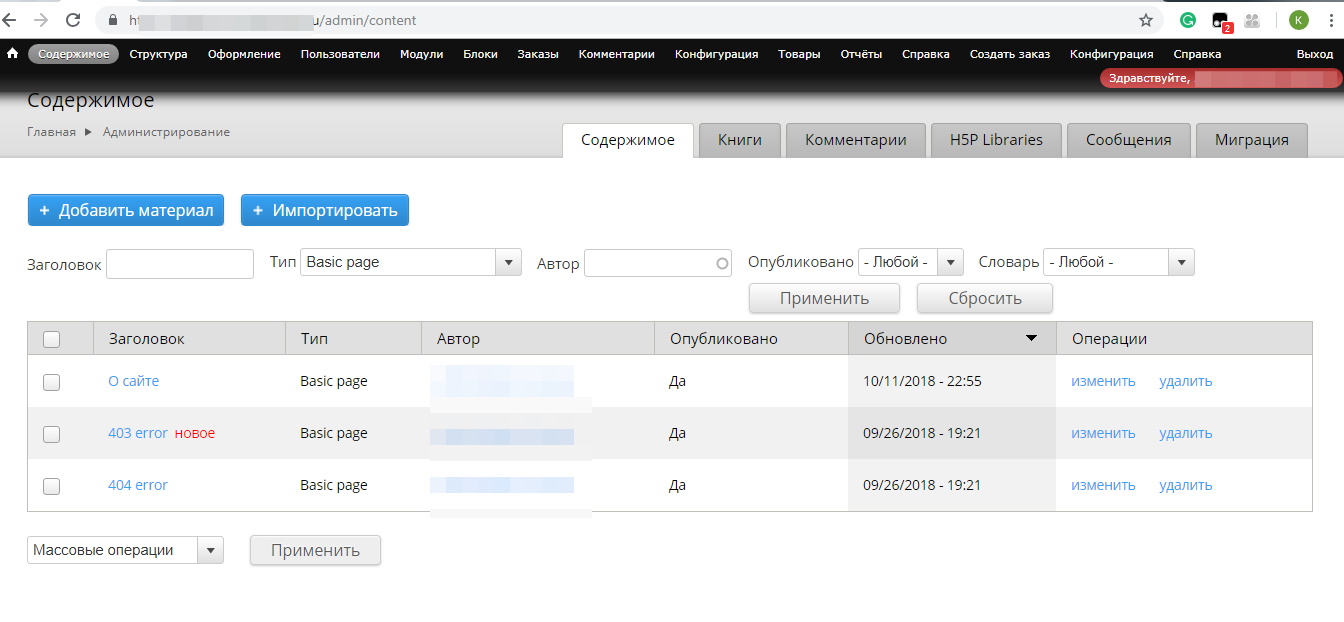
Проблема в том, что страницы со статусом 200, не отображаются на странице с списком всех нод в содержимом. Придется их удалять вручную? Или можно как-то по списку URL, например, через drush?
Почитайте про robots.txt, sitemap.xml, как Яндекс индексирует сайты...
По ссылке, что привел выше - всё есть.
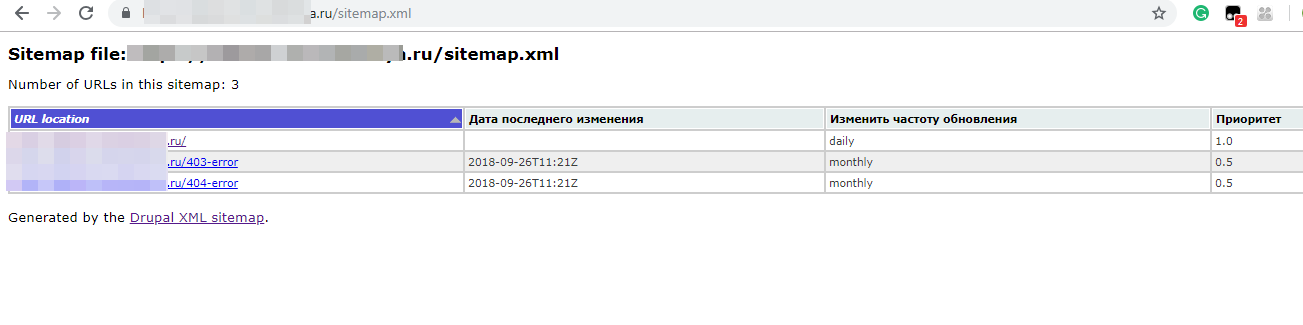
И в sitemap не нужно пихать 403 и 404 страницы.
Ответ будет в друпаловском robots.txt.
По неудаленным нодам, которые отображались в поиске яндекса, но не отображались в содержимом /admin/content, удалось их найти через UI: это были товары, они отображались в товарах /admin/commerce/products. В содержимом некоторые тоже можно вывести вручную, выбрав в фильтре соответствующий им тип материала, например, shoes, hats и т.д. Некоторые были удалены вместе с ненужными типами товаров-материалов. Но часть остатся, например отображается

Go green with Drupal Commerce Reusable Tote Bag
на node/15
При попытке редактирования
Notice: Undefined index: bags_cases_node_form в функции drupal_retrieve_form() (строка 807 в файле .../includes/form.inc).
Warning: call_user_func_array() expects parameter 1 to be a valid callback, function 'bags_cases_node_form' not found or invalid function name в функции drupal_retrieve_form() (строка 842 в файле ...includes/form.inc).
Несколько страниц осталось в поиске и вообще не представляю, как их удалить, после попытки удалить вручную со страницы редактирования ноды, страница не удалилась, но повторно при попытке редактировать выдается сообщение
"Notice: Undefined index: bags_cases_node_form в функции drupal_retrieve_form() (строка 807 в файле .../includes/form.inc).
Warning: call_user_func_array() expects parameter 1 to be a valid callback, function 'bags_cases_node_form' not found or invalid function name в функции drupal_retrieve_form() (строка 842 в файле /...includes/form.inc)."
Эти строки
c 800 по 846
// yet have an entry for the requested form_id.
if (!isset($forms) || !isset($forms[$form_id])) {
$forms = module_invoke_all('forms', $form_id, $args);
}
$form_definition = $forms[$form_id];
if (isset($form_definition['callback arguments'])) {
$args = array_merge($form_definition['callback arguments'], $args);
}
if (isset($form_definition['callback'])) {
$callback = $form_definition['callback'];
$form_state['build_info']['base_form_id'] = isset($form_definition['base_form_id']) ? $form_definition['base_form_id'] : $callback;
}
// In case $form_state['wrapper_callback'] is not defined already, we also
// allow hook_forms() to define one.
if (!isset($form_state['wrapper_callback']) && isset($form_definition['wrapper_callback'])) {
$form_state['wrapper_callback'] = $form_definition['wrapper_callback'];
}
}
$form = array();
// We need to pass $form_state by reference in order for forms to modify it,
// since call_user_func_array() requires that referenced variables are passed
// explicitly.
$args = array_merge(array($form, &$form_state), $args);
// When the passed $form_state (not using drupal_get_form()) defines a
// 'wrapper_callback', then it requests to invoke a separate (wrapping) form
// builder function to pre-populate the $form array with form elements, which
// the actual form builder function ($callback) expects. This allows for
// pre-populating a form with common elements for certain forms, such as
// back/next/save buttons in multi-step form wizards. See drupal_build_form().
if (isset($form_state['wrapper_callback']) && is_callable($form_state['wrapper_callback'])) {
$form = call_user_func_array($form_state['wrapper_callback'], $args);
// Put the prepopulated $form into $args.
$args[0] = $form;
}
// If $callback was returned by a hook_forms() implementation, call it.
// Otherwise, call the function named after the form id.
$form = call_user_func_array(isset($callback) ? $callback : $form_id, $args);
$form['#form_id'] = $form_id;
return $form;
}
Первое - судя по тому что "создана одна страница" - вы рано паникуете. Возможно дистрибутив проиндексировался, и теперь потихоньку страницы выкидываются.
Второе - прогоните сайт от анонима каким нибудь парсером (например Seo frog spider), найдите ссылочки на битые страницы и удалите их.
Спасибо
Там есть страницы с рекламой сумок, футболок, чехлов для телефонов с символикой Commerce kickstart. Предполагалось эти страницы удалить, чтобы они вообще изначально не индексировались. Они были удалины со вкладки admin/content. Но оказалось, что часть была в товарах и проиндексировалась. Тогда были удалены подвиды товаров (сумки, обувь и т.д.) вместе с нодами этих подтипов. Некоторые такие товары были удалены со вкладок node/number/edit
Но некторые после этого всего остались и есть в списке обхода и "страницы в поиске" Яндекса.
Как удалить? Вопрос, как удалить? у меня их нет ни в списке товаров, ни в списке amin/content. Когда из яндекса открываю сслыку, она открывается и есть кнопка "редактировать"
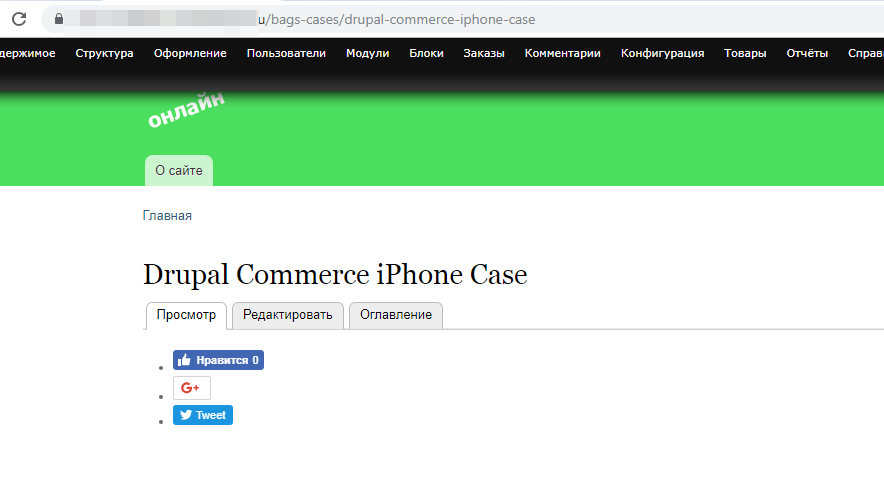
Когда нажимаю "редактировать" выдется страница с предупреждением

Как еще можно удалить?
И еще есть три проблемы с индексированием
1) В диагностике сайта выдается сообщение
"Значительная часть страниц сайта не содержит мета-тег , или он некорректно заполнен. Это может негативно повлиять на представление сайта в результатах поиска."
Это нужно исправлять? Или можно так оставить?
Верно ли я понимаю, что нужно поставить модуль Metatag и в нем настроить?
А где на /admin/config/search/metatags?
Или мне просто нужно заполнять вручную анонсы?
Или где-то еще [node:summary]?
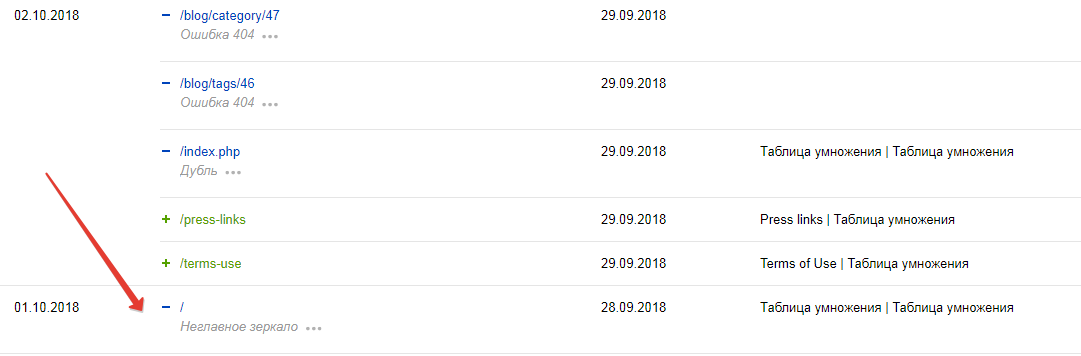
2)Так как удалить страницы пока не знаю как, попробую их закрыть от индексирования.

Делаю например для такой страницы
User-agent: *
Disallow: /drinks/guy-mug
Верно?
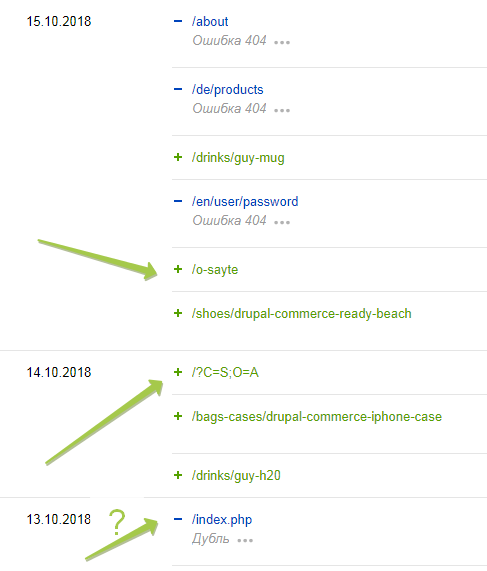
3)В поиске в качестве главной /?C=S;O=A
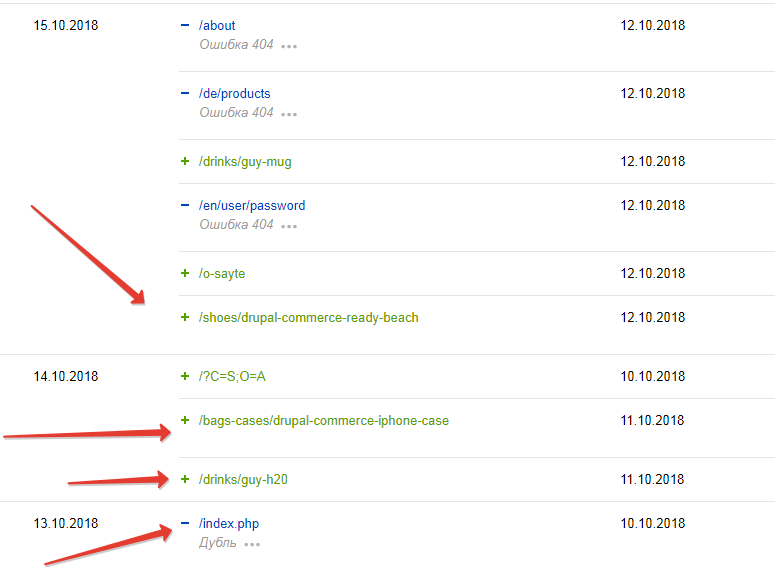
а страница /index.php исключена как дубль
Ну еще в довесок этому
4) Не всегда отображается админ меню, когда я в браузере под админом. Когда не вбивается ввожу в адресной строке вручную /user/login, открываю страницу редактирования своего профиля и "сохраняю". Полсе этого открывается админ меню
Пока лишние страницы пришлось скрыть в роботс

для быстроты, если придется на других сайтах это делать использую
echo Disallow: /blog/cmt-commerce-customizable-products/ >> robots.txt
echo Disallow: /storage-devices/commerce-guys-usb-key/ >> robots.txt
echo Disallow: /ad-push/ad-push-go-green/ >> robots.txt
echo Disallow: /products/ >> robots.txt
echo Disallow: /service-agreements/ >> robots.txt
echo Disallow: /service-agreements/ >> robots.txt
echo Disallow: /drinks/guy-mug/ >> robots.txt
echo Disallow: /shoes/drupal-commerce-ready-beach/ >> robots.txt
echo Disallow: /bags-cases/drupal-commerce-iphone-case/ >> robots.txt
echo Disallow: /drinks/guy-h20/ >> robots.txt
адреса взяты из по-прежнему индексирумых страниц со вкладки "страницы в поиске" Яндекса
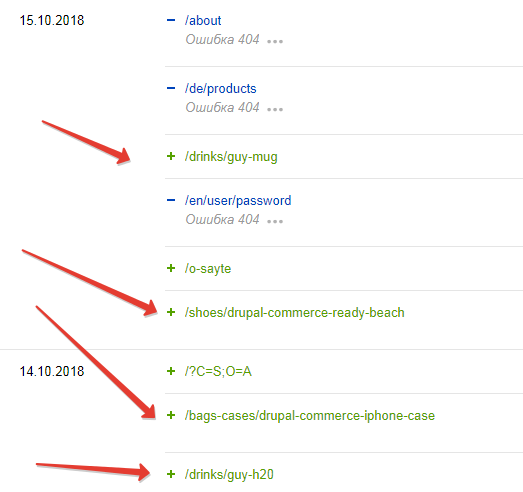
Почему индексирует /
/?C=S;O=A
вместо index.php и нормально ли это, пока не пойму
(лишние, которые не получилось удалить, выделены красным)
(нужные, которые не закрываю, выделены зеленым)
Почитайте про метатег canonical, вероятно это вас успокоит, но не факт)
Спасибо.
Т.е. вы думаете, что у меня есть две одинаковые страницы
/?C=S;O=A
и
index.php
И основной из них является /?C=S;O=A, поэтому index.php просто с ней связна каноникалом? А откуда вообще взялась эта страница /?C=S;O=A?
У всех так на свех сайтах на семерке или на коммерс?
Я ничего не думаю, ибо гадать в вакууме дело неблагородное.
Я лишь обратил твое внимание на метатег и его значение. А там уже смотреть конкретный случай надо.
Спасибо. А как мне узнать, откуда эта страница взялась в дистрибутиве моем? Или Вы предлагаете не искать, а для нее каноникал добавить на index.php, чтобы последняя основной была из этих двух?
Или может эту странную просто заркыть тоже от индексриования, тогда index.php не будет считаться дублем?
index.php - это вообще моветон. Друпал отлично выдает главную на site.ru без всяких индексов.пхп/хтмл.
А если легаси? Ну то есть допустим на старом сайте было index.html, и после переезда на новом сеошник просит так же оставить?
Это вопрос к сеошнику.
Для решения вопроса есть 301 редирект, есть каноникал.
Вполне себе рекомендуемые ПС методы смены урлов.
Так я только за. Но у меня почему-то адрес получается главной.
site.ru/?C=S;O=A
Вот скрин из яндекса ссылки, ведущей на главную

Вы сейчас загадите свой домен так, что придётся покупать новый. На будущее имейте в виду, в robots.txt всегда прописывайте Disallow: / до тех пор, пока сайт не готов к запуску.
Спасибо. Наверное, так и сделаю

Помещаю перед всеми allow и не стираю их?
и на всякий случай в конце (не знаю, в каком порядке робот читает файл, и что приоритетнее, первая настройка или последующая)
В начале достаточно. Главное потом не забыть убрать))
Сайт был перезалит на чистый Друпал с нуля, но проблема сохранилась. Через пару недель у Яндекса снова в индексе эта страница.
site.ru/?C=S;O=D
Ведет на главную
На хостинге говорят, что
"...вместе с адресом страницы указаны два параметра.
Видимо где-то на сайте есть адрес в таком виде и поисковики проиндексировали его".
Предлагают в личном кабинете поисковиков исключить этот адрес из индекса.
Откуда она теперь взялась на чистом Друпале я не пойму.
Где можно искать причину?
Из вариантов ее прикрыть получается:
1)настроить каноникал
2)в роботс disallow
3)сделать с нее редирект 301
4)через вебмастер ее исключить (пока только не пойму как)
5)все же найти причину и ее устранить.
Какой способ из этих Вы порекомендуете?
Смотрю внимательнее описание Яндекса:

вероятно все равно нужно в роботс прописывать даже если в панели удалять, иначе может отклонить удаление
Верно ли будет если я в роботс припишу как на скриншоте
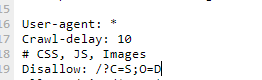
User-agent: *
Crawl-delay: 10
# CSS, JS, Images
Disallow: /?C=S;O=D
и потом ее же исключу в Яндексе
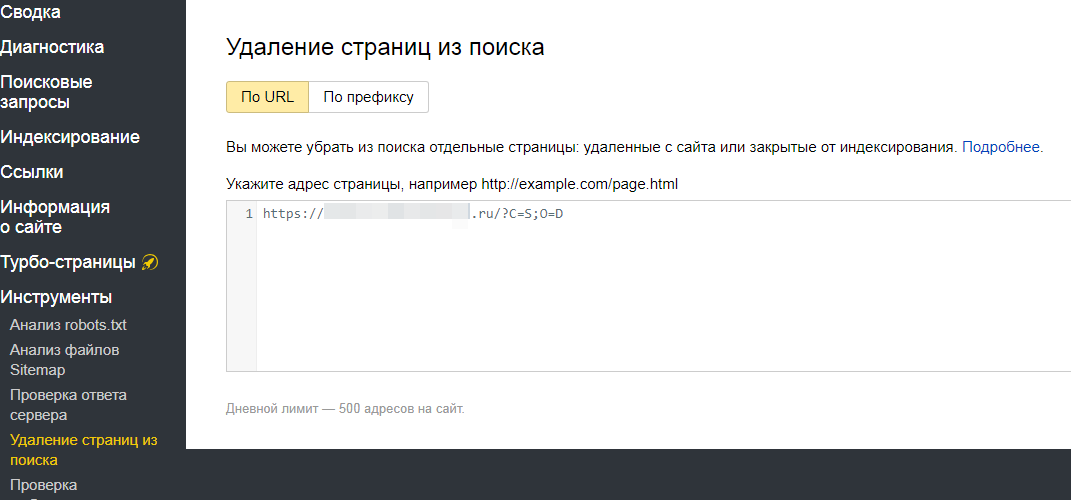
Все это правильно будет?
В результате Янжекс не удалил из поиска эту страницу

Возможно, потому что в роботс было как на скриншоте выше, а вставилось в Яндекс /?C=S;O%3DD
т.е. добавился % вместо второго =
Буду еще пробовать именно так прописать в роботс
Кто-то еще может подсказать, что с ней делать?
Чтобы вебмастер удалил - должен быть код 404 у урла.
Все остальное он удаляет из индекса по своему усмотрению.
Вы продолжаете бороться с мельницами и хотите в этом помощи?
Уже давно рассказали про каноникал, про роботс.
Я уверен, что у вас там полно других более значимых задач для SEO, чем эта лабуда, которая вылетит как "неканоничная" через время.
Лучше потратьте свое время на полезные задачи.
Так я же пишу что там сбой какой-то с % получился и роботс не сработал в паре с панелью Яндекса.
Т.е. когда Яндекс пишет, что главная - это дубль какой-то левой страницы, то это лабуда?
Так нужно настроить тогда чтобы Яндекс разобрался. Сам он не может нормально решить, какая каноническая, каждый день то главную выкидывает из индекса, то дубль и для главной пишет что дубль.
Как указать, что эта страница дубль с помощью каноникал? С модулем типа метатег или как-то вручную где-то прописать, я не пойму?
Вот здесь предлагают удалить
Disallow: /index.php
Кто-то пробовал это?
Что думаете об этом?
Также сейчас в процессе настройки на /admin/config/system/site-information
выяснилось что главной на сайте была /node
У кого-то было такое?
Как такое могло получится, это либо по умолчанию, либо какой-то модуль добавил? Потому что вручную такого не делалось точно.
Это настройка по умолчанию. И модуль globalredirect с этим прекрасно справляется. У вас де стоит globalredirect?
Спасибо. Да.
А как он это исправляет?
Ну можно же и просто стереть node? (оставить это поле пустым, тогда глобал редиректу просто не придется ничего исправлять)?
И еще вопрос по страницам ошибок:
Верно ли я понимаю, что если я хочу создать свою страницу 404, 403, то нужно
создать страницу, как мне надо например типа page (например с адресом /my404)
Потом на
admin/config/system/site-information
В поле
"Введите путь, на который будет выполняться перенаправление при возникновении 403/4-ей ошибки (доступ запрещён)."
ввести адрес созданной страницы
например

Обновление по ситуации с дублем главной


Дубли продолжают появляться (их много, отличие может быть только в одной букве)
и еще один
Причем появление их совпадает с падением в индексе
______________________________________________________________________________________
Картина количества посетителей


(при чем что контент не менялся и ничего не делалось в этот период почти)
______________________________________________________________________________________
Да, они со временем распознаются как дубли. Но не ясно, откуда они берутся?
и
______________________________________________________________________________________
А если сделать
Disallow: /?C
или
Disallow: /?
Это запретит индекс всех адресов, которые начинаются на эти символы?
Может так сделать?