Опубликовал месяца 3 назад на drupal.org модуль и забыл сделать тут анонс...
И нигде не делал анонс, но западные товарищи таки модуль нашли и уже стали постить баги и просить новые фичи.
Короче, - пришло время снова вернуться к модулю и ещё больше его улучшить, поэтому хочу услышать пожелания/баги от русского сообщества, а затем я уже возьмусь там что-то править.
Итак, модуль формирует семантическое ядро сайта.
Как он это делает?
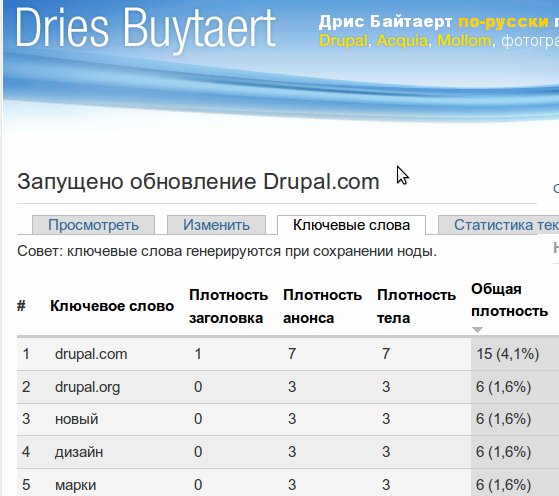
При сохранении ноды её текст (боди), анонс, заголовок парсятся на предмет ключевых слов, которые вычисляются на основании частоты вхождений.
То есть в настройках модуля задаётся порог повторов, а также количество слов в ключевых фразах. Таким образом каждая нода получает вкладку ("таб"), который называется "Ключевые слова" и есть список этих самых ключевых слов и ключевых фраз (словосочетаний).
Далее для всего сайта собираются все ключевые слова и на опред. странице их можно все увидеть. В этом списке также показываются частотность в процентах и список нод, в которых это слово встречается.
Вроде бы все описал. Писал по памяти - подробности на странице модуля keywords на drupal.org
Из-за того, что парсить ноды дело достаточно хлопотное, то в модуле есть запуск этого парсера (назовем его "индексация") по крону для нод, у которых ещё нет списка ключевых слов - т.е., которые не проиндексированы модулем.
Кроме того, там реализована система хранения истории настроек модуля, потому что при смене параметров индексации нужно всю работу переделывать заново, а это не так быстро и просто. Работает так: при смене параметров нод, которые были индексированы со старыми параметрами считаются не имеющими ключевых слов и будут по крону заново проиндексированы. Либо это произойдет при открытии таба с ключевыми словами ноды.
Есть список стоп-слов, которые исключаются из индексации, но только русские и английские. Западные товарищи просили дать возможность добавлять другие языки... Думаю, что это нужно будет сделать.
Ещё была задумка получать из яндекса частоты запросов по каждому ключевику, чтобы видеть насколько нода/сайт соответствует тому, что люди ищут. Парсер водстата яндекса есть и даже работает через прокси, но индекс часто их банит за частые обращения и поэтому дело дальше не пошло.
PS. Забыл сказать, что найденные ключевые слова и фразы можно сохранять в любой словарь таксономии, который выбирается в админке модуля. Далее этот словарь можно сделать скрытым (он не показывается), а модуль NodeWords (Metatags) настроить на использование этого словаря для формирования мета тега description.
В общем, - есть место для творчества.


Комментарии
За Яндекс 5 баллов, гугл в топку!
Как можно пользоватся ключевыми словами, кроме оптимизации контента в соответствии с запросами поисковика?
Хочется что-то наподобие тегов в сегодняшнем их понимании.
Нашел есть совместная работа с модулем мета-тегИнтересно почему скачивание этого модуля после 13 декабря прекратилось см таблицу
Счетчик использования основан на количестве обращений модуля обновления (update status) и по-моему частенько бывают какие-то сбои в статистике.
Я так понял, используется собственный парсер материалов. А почему бы не воспользоваться базой от ядерного search?
Собственный используется. Мысль использовать ядерный была, но уже после того как все было сделано...
И, мне кажется, что он не дал бы мне многих возможностей, но я не сильно разбирался...
На базу ядреного поиска полагаться нельзя: в поиске могут отсутствовать некоторые типы нод, но для них все равно полезно было бы генерировать ключевики. Так что собственный парсер имеет смысл.
У меня давно идея такого модуля была. Логичным продолжением была бы генерация анкор-листов в Сапу и аналогичные сервисы ))
Кстати, мета тег keywords является устаревшим. А вордстат Яндекса - ненадежная и зачастую бесполезная вещь, потому что частота запросов сильно искажена запросами самих оптимизаторов.
У меня сложилось впечатление,что поисковики используют свою модель определения плотности того или иного слова.Т.е какой-то очевидный алгоритм здесь не катит.Во всяком случае разница между теми результатами,которые дают общедоступные тулзы и фактическими очень различаются.
Собственный парсер необходим, так как если будет делаться для нескольких языков, то возникнет необходимость в подключении морфологии, иначе все труды будут даром.
Кстати, насколько сейчас используется морфология например для русского языка? Есть ли выделение корней, анализ приставок и окончаний, разделение на части речи?
Далее, семантика это связь слов, а не выделение из контекста и если речь идет о семантике, окружении ключевиков, то тут без своего парсера вообще никуда.
Имхо, в таком варианте оно конечно юзабельно, но нужны годы работы для получения реальных семантических результатов.
спасибо, надо попробовать
а то может я ключевики не так прописывают вообще
Морфологии нет. Я понимаю что для русского языка отсутствие выделения корней и прочего делает такой инструмент почти бесполезным, но я просто не представляю как это можно закодить.
Ашманов вряд ли поделится со мной своими наработками...
Поэтому для английского языка результаты - более-менее, а вот для русского - не очень. Хотя это лучше, чем ничего.
Модуль задумывался прежде всего как помощь копирайтерам - чтобы сразу видеть насколько хорошо написана статья.
Точнее сначала я сам хотел выяснить насколько мои статьи хороши (или плохи).
Надо брать базы и писать (гуглить) работу с ними. Базы можно взять от ispell. Я рыл информацию по этой теме - всё решаемо.
Уже убегаю праздновать НГ, как отраздную пороюсь у себя в закладках, где-то был класс для русской морфологии, определение части речи, основа, корень и т.п. С ним и БД шла какая-то. А в нынешнем состоянии модуль не более чем плотность ключевиков считает
Библиотека phpMorphy - морфологический анализатор для русского, английского и немецкого языков.
Всех с новым годом!!! Владу спасибо за прекрасный модуль)
Спасибо за классный модуль.
С Новым годом!
Правда о друпале
Всем хочу пожелать умножать количество добрый дел в течении всего нового года, чтобы было что вспомнить через год! Ну и много радости, хочу пожелать.
Скачать скрипт phpMorphy - толково. Мне казалось, что это просто нереальная задача... Буду изучать код чуть позже.
Как я себе вижу подключение морфлогии:
Is it all right?
Отличная шутка! Спасибо - посмеялся!!!
Помогите, если не трудно.Локально модуль работает, на хостинге:
Warning: preg_replace() [function.preg-replace]: Compilation failed: support for \P, \p, and \X has not been compiled at offset 1 in .......PCRE (Perl Compatible Regular Expressions) Support enabled
PCRE Library Version 6.6 06-Feb-2006
PHP Version 5.2.6
Что не так? Или PRCE пересобирать?
Решение : пересобрать PRCE с поддержкой UTF-8
PS: Всех с новым годом.
Задумка хорошая, реализация... под вопросом. Объясню почему: из СЕО примочек keywords и description больше всего нравилась реализация в движке DLE, принцип там такой, есть возле каждого из полей по кнопке, нажимая на которые в полях генерятся ключевые слова и описание(без перезагрузки страницы). Быстро просматривашь, редактируешь если что не так и сохраняешь.
Почему мне не понравилось в этом модуле. Сразу оговорюсь, что времени как всегда нет( поэтому поставил, потыкал, не понравилось, снес. Это ни в коем разе не упрек создателю, он как раз молодец, но и есть над чем поработать...
Поставил модуль на уже работающую тестовую систему, на которой до этого уже прижился nodewords. В его полезности я тоже немного сомневаюсь, потому что хоть он и дает meta поля для каждой ноды, но обычно у редактора нет времени и желания вручную их заполнять. Допустим описание(description) он сейчас может брать из тизера или текста, а с ключевыми словами все плохо.
Включил новый модуль, создал для него словарик(таксономия) но не привязывал к типам материала, в настройках модуля указал этот словарик. Полазил по нодам view-edit-save, все хорошо, генерятся ключевые слова, добавляются теги таксономии в словарь, но ОП-ПА - в низу каждой ноды помимо тематических тегов(те что уже ранее были) появляется куча "мусора", сеошных тегов из словаря, сгенерированного этим модулем. Ладно, думаю полезу руками уберу лишнее, полез в ноду, строку таксономии не нашел, но это и понятно - не привязывал к типу материала. Полез, привязал. В ноде нашел строку таксономии(ключевых слов), вычистил... сохраняю - не тут то было, ключевые слова то уже в таблице таксономии и очевидно связаны с этим номером ноды, поэтому "мусорных" тегов не поменьшало, как и ключевых слов в keywords. Идем опять в edit ноды, там стоит в поле таксономии тот же список сгенерированных ключевых слов...
Итог - все что установлено "на выход", модуль в закладки на будущее. Автору респект и повод для размышления.
Спасибо за модуль. Полезная вещь.
По поводу морфологии: может подойдёт этот класс - Эвристическое (без словаря) извлечение корня из русского слова
И ещё: после подключения модуля выдавал много ошибок на 36 строку файла keywords.pages.inc.
После того, как в строке
<?php$sql = "SELECT SUM( density ) AS count FROM keywords_nodes";
?>
название таблицы взял в фигурные скобки ошибки исчезли.
Уотсон, очевидно Вы используете таблицы с префиксом;)
Yes!
Очевидно, автор модуля по запарке отрёкся от друпал-стандартов
Интеграция с nodewords - скорее приятный побочный эффект, но всё же, если не ошибаюсь - я описывал как нужно это сделать. Есть модуль, который позволяет скрыть вывод тегов определённого словаря - ставите, скрываете словарь в который сохраняются ключевики и их не видно на странице ноды.
может я в прошлый раз не так четко сформулировал пожелания, но хотелось бы иметь более гибкий и полный контроль)) Я понимаю, что могу нарваться на ответ: "надо, так иди и сделай!" и это правильно, но думаю если учесть пожелания, то модуль будет пользоваться большим(ударение на первый слог) спросом. Сейчас на серьезный проект я его пока не поставлю(.
Я не буду плакать! Я сильный.
Модуль создавался для реализации моих целей (эгоизм?!) и, добавление новых фишек, которые мне интересны, - имеет приоритет перед всем остальным. А исправление багов имеет приоритет перед всем.
Но патчи принимаются!
очень нужно и интересно что бы найденные модулем ключевые слова или фразы связать с терминами таксономии и что бы статья при отправке автоматически к ним присоединялась
Собственно, сие, совершенно не проблема, правда код не смотрел
Спасибо!
ПС сейчас не смотрят keyword
но для статистики этот модуль супер!
буду смотреть как грузит серв.
на многоязычном сайте не пошло.
пошла движуха это хорошо. Модуль нужный может один из основных- его бы допилить до нормы.
Огромное спасибо. Хороший модуль.
з.ы. правда, с PostgreSQL выдаёт рекордное число ошибок.
Подскажите, что я не так сделал?
на странице мойсайт.ru/admin/content/keywords вываливается куча ошибок:
user warning: Table 'e3w_sale.keywords_nodes' doesn't exist query: SELECT SUM( density ) AS count FROM keywords_nodes in /home/e3w/public_html/orisale.ru/sites/all/modules/keywords/keywords.pages.inc on line 36.
warning: Division by zero in /home/e3w/public_html/orisale.ru/sites/all/modules/keywords/keywords.pages.inc on line 69.
warning: Division by zero in /home/e3w/public_html/orisale.ru/sites/all/modules/keywords/keywords.pages.inc on line 69.
и так далее
Спасибо! разобрался. поменял 35 строчку на
$sql = "SELECT SUM( density ) AS count FROM {keywords_nodes}";
изучаю модуль дальше!
Влад, реальный косяк в этой строке. Имя таблицы надо в фигурные скобки заключать.
в закладки
Модуль жить дальше будет?